


Building data-heavy applications is always hard for developers, it is even more challenging when developers have to deal with blockchain data. The process of accessing or extracting blockchain data is not only slow but it is also complex due to the built-in functionality of blockchain and smart contracts. Smart contracts are designed to store data, transfer assets, and perform other operations within a decentralized network or blockchain. Performing basic read operations in a smart contract is relatively easy. For example, In the case of any NFTs project like Bored Ape Yacht Club, we can perform basic read operations on smart contracts like getting the owner of a certain Ape, getting the content URI of an Ape based on their ID, or the total supply, as these read operations are programmed directly into the smart contract, if we wanted to query for apes that are owned by a certain address, and filter by one of its characteristics, we would not be able to get that information by interacting directly with the contract itself. We can see that the more complex operations, such as filtering and aggregating data, are much more difficult to achieve. This is because, the storage capacity of the blockchain is limited, which can be a challenge when working with large datasets. Since each node in the network must store a copy of the entire blockchain, storing large amounts of data can become impractical, especially when considering the cost of storage and processing power.
In the past, developers faced challenges in accessing and utilizing blockchain data due to limitations in functionality. To bridge this gap, they resorted to constructing centralized indexing servers as a workaround. This approach required developers to operate their full nodes to access the data stored on the blockchain. The indexing servers would retrieve data from the blockchain, store it in a separate database, and provide an API for developers to interact with. However, this solution had significant drawbacks.
Firstly, the process of maintaining and operating these centralized indexing servers was resource-intensive and time-consuming. Running a full node and continuously synchronizing it with the blockchain required substantial computational power and storage capacity. Additionally, as new blocks were added to the blockchain, the indexing servers had to update their database, which further strained their resources.
Secondly, the reliance on centralized indexing servers was not cost-efficient. Setting up and maintaining these servers incurred expenses, such as hardware, infrastructure, and maintenance costs. These expenses could be burdensome for developers, particularly for projects with limited resources or smaller teams.
Moreover, building and managing centralized indexing servers introduced complexity and potential points of failure. The task involved intricate programming, database management, and API development, which increased the likelihood of errors. Developers had to carefully design and maintain the servers to ensure accurate and reliable data retrieval. This reliance on external servers also made the system vulnerable to various risks. Users had to trust the indexing server teams to operate the servers correctly and securely. However, there were uncertainties, such as the possibility of the projects going out of business, modifying data for strategic reasons, being acquired by other entities, or making inadvertent mistakes. These factors eroded the trust and reliability of the system, undermining the desired advantages of blockchain technology.
Consequently, this situation resembled the centralized nature of traditional web applications (Web 2.0) where users relied on intermediaries for data access and manipulation. It was evident that a more decentralized and efficient solution was necessary to overcome the limitations and challenges of performing complex operations on blockchain data.
Therefore, developers began exploring alternative approaches that minimize reliance on resource-intensive and centralized indexing servers. They sought ways to directly access and process blockchain data without sacrificing security, reliability, and decentralization. This involved the development of new technologies, protocols, and tools that provide efficient and user-friendly methods for interacting with blockchain data. By leveraging these advancements, developers aim to empower users to perform complex operations on blockchain data while maintaining the core principles of decentralization and trustlessness.
A solution to this problem is to use decentralized indexing and querying services, this is where The Graph comes to rescue us. The Graph is a decentralized protocol for indexing and querying data from blockchain networks.The Graph provides a marketplace of subgraphs, which are open APIs that index and expose specific data from the blockchain. Developers build their subgraphs, which can be used to index and query data from specific smart contracts. The Graph enables developers to leverage the power of the blockchain network without having to run a full node or rely on centralized indexing servers.
How do the subgraphs work?
In simple words, a subgraph is a piece of code written by a developer that defines how to ingest, index and serve data. A subgraph extract data from the blockchain, process it and stores it so that it can be easily queried via GraphQL. Developers use subgraphs to feed data to the front-end interface of their application. Developers define the criteria for the index by writing a GraphQL schema, and mapping functions are created to map the relevant data to the schema. The subgraph is then deployed and made available for other developers to use, making it easier for them to find and use specific data on the blockchain.
At the core level, a subgraph can be considered an ETL process in the context of blockchain data. ETL stands for extraction(E), transformation(T), and loading(L) of blockchain data. Let's delve into each of them in detail:

- Extraction: The extraction process involves retrieving data from the blockchain. In the case of Ethereum, the developer typically interacts with the Ethereum client or a service provider's API to extract relevant data. This can include fetching blocks, transactions, events, and other information from the blockchain. In the case of the subgraphs, the extraction process is done by the Graph node JSON-RPC polling in which The Graph node connects to the target blockchain network and listens for events emitted by smart contracts or other blockchain entities. It utilizes specialized libraries or APIs provided by the blockchain platform to monitor the network for new transactions, blocks, or specific events.
JSON-RPC polling refers to a method of communication between a client and a server using the JSON-RPC protocol. In this approach, the client regularly sends requests (polls) to the server to retrieve updated information or perform specific actions.
Transformation: After extracting the raw data, it needs to be transformed into a structured format that is suitable for analysis and querying. The transformation step involves cleaning, normalizing, and organizing the data. This process may include tasks such as data type conversions, merging related data, filtering irrelevant information, and applying business logic to create derived data points. The goal is to convert the extracted data into a consistent and coherent format.
Loading: Once the data has been transformed, it needs to be loaded into a database for efficient storage and retrieval. The transformed data is loaded into a dedicated database, often optimized for fast and efficient querying. This step ensures that the data extracted and transformed by the subgraph is readily available for developers to query and utilize in their applications. By preloading the data into a database, the subgraph minimizes the need for real-time interactions with the blockchain, leading to faster response times and improved performance.
After the database is populated with the extracted blockchain data, the Graph node exposes a query API that developers can interact with. This API provides a standardized interface to retrieve specific subsets of data from the subgraph based on developers' queries, allowing them to access the blockchain data easily and efficiently. By following these steps, a subgraph developer can extract data from the blockchain, transform it into a usable format, load it into a database, and enable users to query and interact with the data efficiently. This process is crucial for building decentralized applications on top of blockchain protocols, as it provides a structured and accessible layer for blockchain data.
Limitations of Subgraphs: Syncing, Composability and Real-Time Data Lag
A pretty awesome solution, but like any technology, subgraphs also have their limitations. One significant challenge with subgraphs is the time it takes for them to sync and update with the blockchain. As blockchains continuously grow and new data is added, subgraphs need to stay synchronized to provide accurate and up-to-date information. However, the syncing process can be time-consuming, particularly for large blockchains with extensive transaction histories. This delay between blockchain updates and subgraph synchronization means that there can be a lag in accessing the most recent data, which can be a hindrance for developers and applications that require real-time or near-real-time information. It's an aspect that developers and users need to consider while leveraging subgraphs for their data extraction and querying needs.
Another notable issue with subgraphs is their isolated nature at the indexing level, which can impact the overall efficiency and flexibility of data extraction. Each subgraph operates independently and focuses on indexing and serving data for specific smart contracts or dApps. While this isolation allows for modularity and specialization, it also means that data from different subgraphs are not easily combinable or cross-referenced within the indexing process. This lack of composability can result in limitations when developers want to access and analyze data that spans multiple subgraphs or requires aggregating information from various sources. It may require additional efforts to manually reconcile data from different subgraphs, potentially leading to increased complexity and reduced efficiency in data extraction and analysis. The isolated nature of subgraphs can hinder the ability to leverage synergies between different datasets. By treating each subgraph as a separate entity, it becomes challenging to create connections and derive insights from the interplay of data across multiple blockchain applications or smart contracts. This limitation may restrict the full potential of data analysis and exploration, hindering the development of complex, data-centric applications.
Enhancing Subgraph Performance through Innovations
We saw that the current tech state of the subgraph has some scope for improvement, one is to tackle large syncing time which occurs due to the linear extraction process used by The Graph Node to extract smart contract data and the other issue is isolation. So it is clear from this, if we want to improve the performance of subgraphs we need to look into these two things. It appears that to improve the overall performance of the subgraphs we need a solution that can improve the extraction(E) layer of the subgraphs or a technology that can improve the extraction speed of The Graph node.
In 2021, StreamingFast, a company specializing in scalable, cross-chain architecture for streaming blockchain data, joined The Graph as a core protocol developer. Their primary goal was to enhance the extraction process of subgraphs. As part of the Graph Core Developer team, StreamingFast introduced Firehose, a high-performance data ingestion method from blockchains, integrating it into The Graph. Initially, complex subgraphs could take weeks to sync, causing delays for developers working with The Graph. To address this issue, StreamingFast developed a prototype called Sparkle, significantly reducing the sync time from weeks to hours for a particular subgraph. Building on this success, StreamingFast expanded Sparkle's capabilities, resulting in the creation of substreams that can scale across all subgraphs on different chains.
What are substreams?
Substream is a new powerful parallelized engine to process blockchain data developed for The Graph Network by StreamingFast. The Substreams engine is responsible for running developer-defined data transformations to process blockchain data.
Earlier we defined a subgraph as an ETL process in the context of blockchain data. ETL stands for Extract, Transform, and Load. In the context of blockchain data, ETL refers to the process of extracting data from the blockchain, transforming it into a format that can be used by applications, and loading it into a data warehouse or database. In the new subgraph architecture, the extraction of blockchain data will be carried out by a graph node equipped with Firehose capabilities. Subsequently, the transformation of this data will be performed utilizing the substreams functionality.
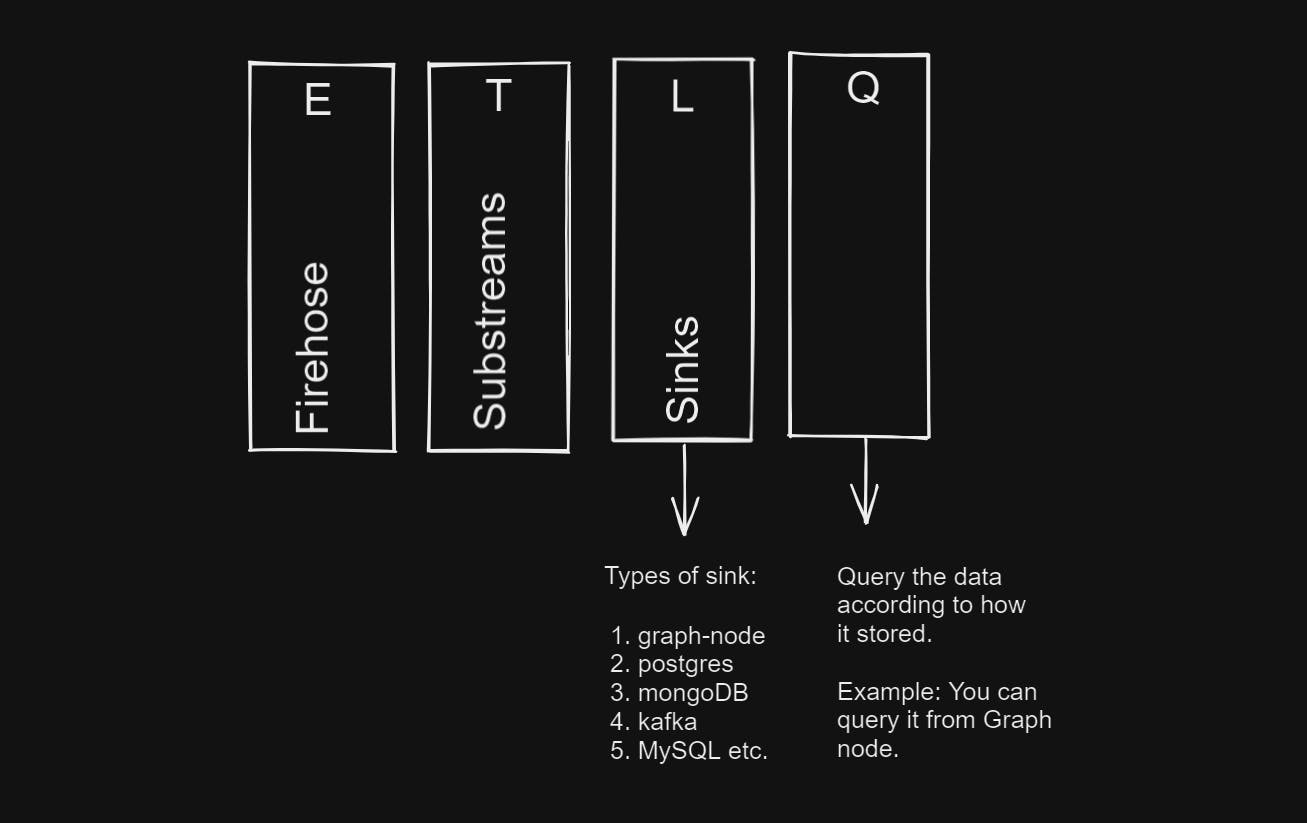
Substream is a rethinking of the transformation layer, where instead of writing subgraph handlers in AssemblyScript, you will write substream module in Rust. Substreams Modules are small pieces of Rust code running in a WebAssembly (WASM) virtual machine. Rust's performance and safety features, combined with the extensive library ecosystem, empower Substreams to handle complex computations and transformations efficiently. This powerful combination ensures Substreams' adaptability and effectiveness in processing blockchain data on-the-fly.
Benefits of using substreams:
Speed: Substreams prioritize speed through their parallelized architecture and streaming-first design, ensuring high throughput for indexing blockchain data efficiently.
Composability: Substreams offer composability, enabling easy combinations of modules to create complex indexing pipelines. This flexibility ensures scalability, allowing developers to tailor indexing solutions according to specific requirements.
Reusability: Substreams emphasize reusability, allowing developers to employ them for multiple indexing tasks. This cost-effective approach saves time and effort by avoiding the need to recreate indexing logic for different tasks.
Custom sinks: Substreams support custom sinks, facilitating seamless integration with developers' preferred data storage or analytics solutions. This flexibility empowers developers to create customized indexing solutions aligned with their unique needs.
Scalability: Substreams are designed with scalability in mind, effortlessly handling large volumes of data. Their architecture enables seamless expansion to accommodate growing demands.
Flexibility: Substreams offer exceptional flexibility, capable of indexing a wide range of blockchain data. This versatility allows for diverse applications and use cases, accommodating different types of data in the blockchain ecosystem.
In conclusion, the introduction of substreams, firehose, and custom sinks within The Graph ecosystem has revolutionized the extraction, transformation, and loading (ETL) layer of subgraph development. These advancements have addressed critical limitations and challenges faced by developers working with blockchain data. Substreams offer speed, composability, reusability, customizability, scalability, and flexibility, making them a powerful solution for indexing blockchain data efficiently. The integration of Firehose has significantly reduced syncing times, enabling near-real-time access to up-to-date information. Additionally, the use of custom sinks allows seamless integration with preferred data storage or analytics solutions. By leveraging these technologies, developers can build data-heavy applications on top of blockchain networks while maintaining decentralization, trustlessness, and performance. The Graph has successfully provided a decentralized and efficient solution that empowers developers to perform complex operations on blockchain data, opening up new possibilities for the development of innovative and impactful decentralized applications. You can explore and learn more about substreams here .
If you enjoyed reading my blog, I would greatly appreciate it if you could take a moment to show your support by liking and commenting on it. Your feedback and engagement are incredibly valuable to me and will help me to continue improving and creating content that is informative and engaging. I'll be making a bit of content for The Graph in the coming days. Follow me on Twitter and Hashnode to be alerted about my next article in this series. You can find me on all platforms .@subgraphdev.